When You Come to a Fork in the Code, Take It
The agent read the skill. Then it read the existing code. Then it wrote with the older pattern. Six runs, both variants, every time. Your codebase is the agent's primary teacher — no skill can override it.
The first experiment deleted all the tests and asked the agent to write them from scratch. That's a clean measurement — but it's not how most real projects work. Most projects already have tests. Some of those tests use older patterns. When we gave the agent skills teaching MockMvcTester — the fluent API that Spring Framework 7 introduced — and there were no existing tests to look at, the agent used MockMvcTester. It scored 1.00 on version-aware patterns.
This experiment starts with six existing test files that use the older mockMvc.perform() API. Same skills. Same model. Here is what the agent actually did:
[ 5] Skill(spring-mvc-testing) ← loads the skill
[ 6] Read(mvc-rest-testing-patterns.md) ← reads the reference doc
... reads existing tests, production code ...
[28] Write(PetControllerTests.java) ← writes with mockMvc.perform()
The skill teaches MockMvcTester. The agent reads it. The agent then reads the existing OwnerControllerTests.java, which uses mockMvc.perform(). When it writes its own controller test, it uses mockMvc.perform().
This happened in all 6 runs. Both variants. Every session. Version-aware patterns dropped from 1.00 to 0.30.
TL;DR: When existing code contradicts skill guidance, the agent follows the code. We ran 6 sessions (2 variants, N=3 each) on Spring PetClinic with seed tests that use older patterns. The agent consumed the skills, read the reference docs, and still wrote with the older API — because that's what the existing tests demonstrate. Quality scored 0.667 across all 6 runs: a hard ceiling set by the existing tests, not the prompt or the skills. Behavioral fingerprints diverge (37% fewer expected steps with prompt hardening, 4x fewer redundant reads), but quality converges to the same number. The fix isn't a better prompt. It's better code. All tooling is Java on Maven Central.
The Setup
Same PetClinic (Boot 4.0.1), same model (Claude Sonnet 4.6), same skills. PetClinic ships with high test coverage out of the box, so we stripped most of the tests to drop coverage to 64.9% — leaving 6 test files that compile and pass but use older patterns:
mockMvc.perform()— the established MockMvc API. Spring Framework 7 (which Boot 4 picks up) introducedMockMvcTester, a fluent replacement with better AssertJ integration. Both work;MockMvcTesteris the recommended path forward.- No
flush()/clear()in@DataJpaTestclasses — a JPA testing best-practice gap. Without flushing and clearing the persistence context between writes and reads, assertions hit the Hibernate L1 cache rather than the database, masking potential bugs.
The skills explicitly teach the improved patterns. The remaining test files demonstrate the older ones. The agent's job: write new tests to bring coverage back up to 85%.
This time the experiment is a controlled pair, not a 7-variant ladder. Two variants, one variable: prompt structure.
| Variant | What the agent has |
|---|---|
simple |
Two-line prompt. "Add JUnit tests to improve code coverage." No process guidance. |
hardened-skills |
Seven-step structured prompt. Explicit stopping condition. Instruction to read existing tests first. Guidance on slice selection, version-aware patterns, and what not to test. |
Both variants have the same skills installed globally. Both start from the same 6 remaining test files. 6 sessions total, N=3 per variant. Every tool call logged via Agent Journal.
What the Judge Found
The T2 quality judge scores 6 criteria, two of which use grep enforcement — if the generated tests don't contain MockMvcTester or flush()/clear(), those criteria cap at 0.30 regardless of what the LLM judge thinks. Here's what 6/6 runs produced:
| T2 Criterion | Score | Passed? |
|---|---|---|
| test_slice_selection | 1.00 | Yes |
| assertion_quality | 0.80 | Yes |
| error_and_edge_case_coverage | 0.80 | Yes |
| domain_specific_test_patterns | 0.30 | No |
| coverage_target_selection | 0.80 | Yes |
| version_aware_patterns | 0.30 | No |
| Average (T2) | 0.667 | — |
The 4 criteria the agent passes reflect the model's strong baseline on a known domain — correct test slices, meaningful assertions, edge cases covered, good target selection. The 2 it fails trace directly to the existing test files:
- version_aware_patterns = 0.30: Zero
MockMvcTesteroccurrences. 17–18mockMvc.perform()calls across 5 files. The skill teaches the right pattern. The agent reads it. The agent writes the old one. - domain_specific_test_patterns = 0.30: Zero
flush()/clear()calls in@DataJpaTest. The skill teaches it. The existing tests don't do it. The agent follows the existing tests.
T2 = 0.667 across all 6 runs. Both variants. Every session. The quality ceiling is set by the existing tests, not by the prompt or the skills.
The Numbers
Each run goes through three automated judges. T0: did the build pass? T1: how much did coverage improve from the 64.9% baseline, normalized 0–1. T2: an LLM judge scoring test quality on 6 criteria (the one that caught the exemplar effect above).
| Variant | N | Mean cost | ± | Mean turns | T2 quality | Final cov. |
|---|---|---|---|---|---|---|
simple |
3 | $3.60 | 0.54 | 47.0 | 0.667 | 95.2% |
hardened-skills |
3 | $3.46 | 0.72 | 46.7 | 0.667 | 92.9% |
Per-run breakdown:
| Run | Variant | Cost | Turns | Duration | Final cov. | T1 | T2 |
|---|---|---|---|---|---|---|---|
| n1 | simple | $4.07 | 42 | 20.3 min | 95.3% | 0.608 | 0.667 |
| n1 | hardened-skills | $3.99 | 52 | 16.9 min | 94.6% | 0.595 | 0.667 |
| n2 | simple | $3.72 | 52 | 18.0 min | 94.6% | 0.595 | 0.667 |
| n2 | hardened-skills | $2.62 | 37 | 12.5 min | 89.2% | 0.486 | 0.667 |
| n3 | simple | $3.00 | 47 | 13.0 min | 95.6% | 0.615 | 0.667 |
| n3 | hardened-skills | $3.77 | 51 | 16.4 min | 94.9% | 0.601 | 0.667 |
All 6 runs pass T0 (build success). T2 is invariant at 0.667. Coverage ranges from 89.2% to 95.6% — well above the 85% target. The n2/hardened-skills outlier is interesting: fewest turns (37), cheapest ($2.62), but lowest coverage (89.2%). The agent wrote fewer tests and stopped earlier. It still cleared every gate.
The rightmost column tells the story. T2 does not move. Cost varies. Turns vary. Coverage varies. Quality is locked at 0.667 because the exemplar is locked.
Two Paths to the Same Destination
Both variants produce T2 = 0.667. But they get there differently. The Markov chain analysis reveals fundamentally different navigation patterns despite identical outcomes.
| Metric | simple | hardened-skills |
|---|---|---|
| Orientation phase | 72% of calls | 65% of calls |
| First file read | PetClinicApplication.java |
pom.xml |
| Read order | production code first | existing tests first |
| Redundant reads per run | 16.7 | 4.3 |
| Avg tool calls | 84 | 61 |
| Expected steps (Markov) | 260 | 164 |
The simple agent reads every production file, then re-reads them when it needs to write tests. It does not retain file content across turns. The hardened-skills agent reads existing tests first (as instructed), infers what's needed, and avoids re-reading.
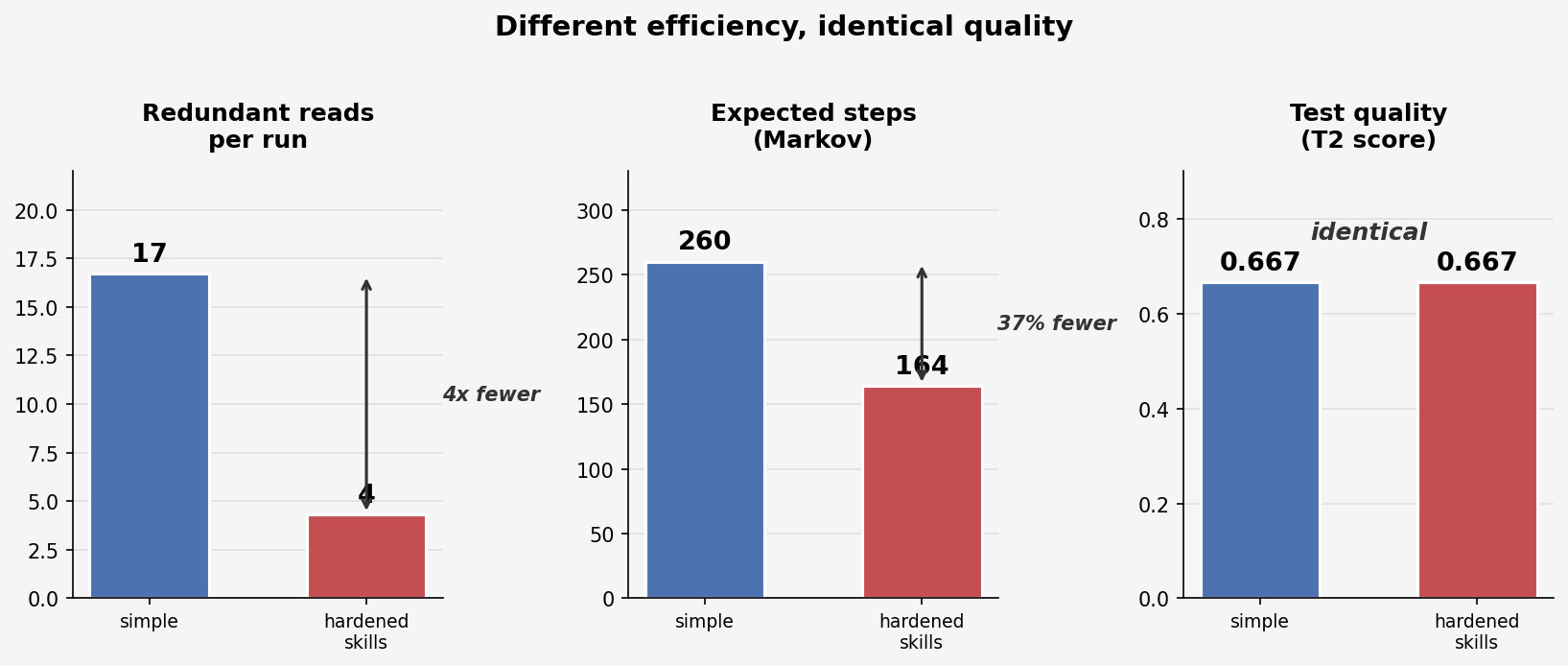
4x fewer redundant reads. 37% fewer expected steps. Same quality. The efficiency story is invisible if you only look at the T2 score.
The state diagram shows why. Each node is a behavioral state the agent can be in; each arrow shows the probability of transitioning between them, with the simple value on the left and hardened-skills on the right.
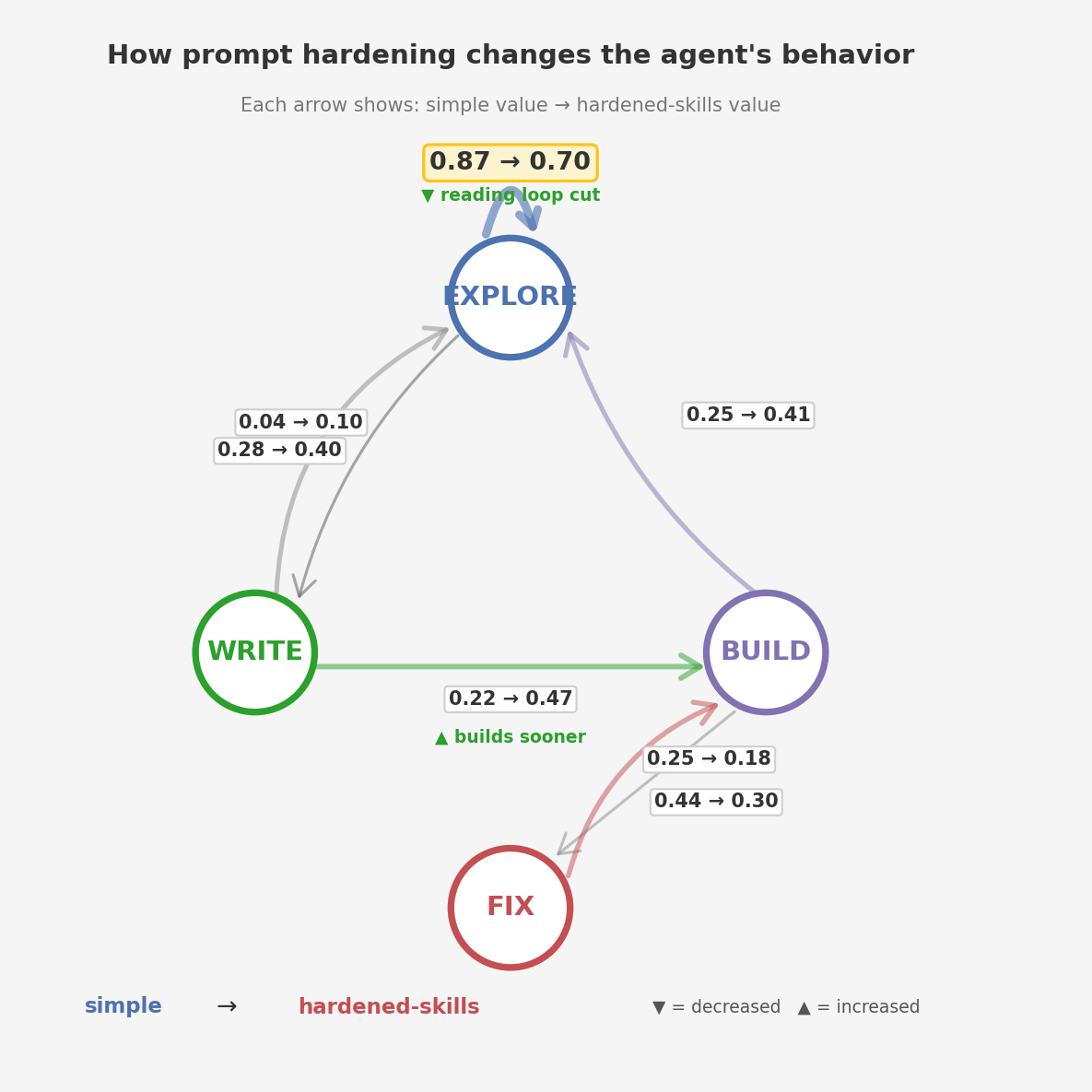
Two changes stand out. The EXPLORE self-loop drops from 0.87 to 0.70 — the agent spends less time re-reading files it already saw. And the WRITE→BUILD arrow more than doubles (0.22 → 0.47) — the agent writes a test and immediately builds it, instead of going back to read more files first.
One counterintuitive finding: hardened-skills has a higher FIX_LOOP percentage (20.1% vs 11.0%). The hardened prompt includes explicit instructions to verify compilation after each batch of writes. The agent follows this — it builds more often, catches errors earlier, fixes them in place. The simple agent writes more files before attempting a build, so its fix ratio is lower but its failures are larger when they hit. Both variants average 1.0 fix cycles per run — PetClinic is easy enough that neither spirals.
The Exemplar Effect: v2 vs v3
This is the central finding. The v2 experiment started from zero tests. Nothing for the agent to mimic. The v3 experiment starts from 6 existing test files using older patterns. Skills are identical. The model is identical.
| v2 (zero tests) | v3 (existing tests) | What changed | |
|---|---|---|---|
| Coverage (simple) | 92–94% | 89–96% | Converges either way |
| T2/T3 quality | 0.783–0.878 | 0.667 | Exemplar patterns cap quality |
| version_aware | 0.70–1.00 | 0.30 | Seed files use perform() |
| domain_specific | 0.70–0.90 | 0.30 | Seeds lack flush/clear |
| JAR_INSPECT | 1.7–17.7% | 0.0% | Boot 4 imports are known |
In v2, the agent sometimes discovered the correct patterns on its own — T3 scores up to 0.878. In v3, with explicit skill guidance and a structured prompt, the agent scores 0.667 — because the existing tests are a stronger signal than the skills.
Providing knowledge does not help when the codebase contradicts it.
The agent reads the skill. It reads the reference document that the skill points to. It sees MockMvcTester explained, with examples. Then it reads OwnerControllerTests.java and sees mockMvc.perform(). When it writes its own test, it writes mockMvc.perform(). This is not a routing failure — the skill fires every time. It is a precedence failure: what the agent sees in the codebase outranks what the agent is told in the skill.
This has a concrete implication. In v2, the highest-leverage intervention was hardening the prompt (+0.07 quality) and adding skills (25% fewer steps). In v3, neither intervention moves quality at all. The highest-leverage intervention is fixing the existing tests.
What This Means for Practice
Three takeaways for anyone running coding agents:
1. Fix the exemplar before optimizing the prompt. The agent will mimic what it sees. If the existing tests use the older API, the agent will use the older API. No amount of skill guidance overrides the codebase. Update the existing tests first. This is the cheapest intervention with the highest expected impact — change 6 files, re-run, predict T2 rises to ≥0.85 (matching v2's quality on the same criteria).
2. Behavioral differences are invisible in pass/fail metrics. Both variants pass every judge. Both produce ~90–95% coverage. The 4x difference in redundant reads and the 37% difference in expected steps are only visible in the tool-call trace. If you only measure outcomes, you miss the efficiency story. The diary matters — not just the grade.
3. Knowledge injection is an efficiency tool, not a quality tool, on known domains. Skills cut the reading loop in half — from 189 cycles on average down to 93. They do not improve quality when the model already knows the domain and the codebase provides contrary examples. The quality lever is the exemplar.
What's Next
v4: Fix the exemplar — but not by hand. We could manually update 6 test files and re-run. That's the cheapest experiment and we'll do it to validate the prediction (T2 rises to ≥0.85). But the real lesson is about agent design.
The v2 experiment showed that the agent has a finite attention budget — "same attention budget, better allocation." Pre-analysis alone regressed quality because the agent's focus was spread too thin — following a plan and discovering patterns and writing tests and fixing compilation errors all in one pass. The fix was separating concerns: pair pre-analysis with skills so each step had the right vocabulary. The broader principle: you don't want to build the mother of all prompts that tries to do everything in a single shot. You want separate, focused steps — each with a clear job and a narrow attention scope.
Upgrading existing tests to Boot 4 best practices is not the same task as writing new tests for coverage. It requires different attention: scanning for mockMvc.perform() and replacing it with MockMvcTester, adding flush()/clear() to @DataJpaTest classes, verifying everything still compiles. That's a "Boot best-practices upgrade" step — skill-driven, focused, run before the test-writing agent starts. Fix the code the agent will imitate, then let it imitate. Same pattern as pre-analysis from v2 (a deterministic step before the AI step), but applied to the exemplar instead of the project structure.
The full research report — all tables, per-run breakdowns, Markov analysis, and figures — is available as a PDF download. Experimental data and analysis scripts: Code Coverage v3 experiment. All tooling — Agent Client, Agent Journal, Agent Judge, Agent Experiment — is available on Maven Central as part of AgentWorks.
The Bottom Line
If you're leading a team that's adopting AI coding agents — or evaluating whether to — here's what this experiment adds to the first one:
- The codebase is the agent's primary teacher. Skills and prompts are secondary signals. If the existing code demonstrates older patterns, the agent will reproduce them — even when it has explicit knowledge of the better approach.
- Quality ceilings come from exemplars, not prompts. T2 = 0.667 across all 6 runs. Two variants, three runs each, identical quality score. The ceiling moved when the existing tests changed (v2 vs v3), not when the prompt changed (simple vs hardened).
- Efficiency gains are still real. 37% fewer expected steps, 4x fewer redundant reads, half as many reading-loop cycles. Prompt hardening and skills make the agent faster. They just can't make it better when the codebase says otherwise.
- Fix the code, not the prompt. The highest-leverage intervention for agent quality is updating the exemplars the agent will see. This is also the cheapest experiment to run — and it's next.
This experiment adds to a growing body of evidence that skills are harder than they look. Vercel found that agents failed to invoke available skills 56% of the time — a simple AGENTS.md file passively loaded into context scored 100% while skills scored 53% by default. Researchers at UC Santa Barbara and MIT showed that skill effectiveness degrades from 55% to 40% as test conditions get more realistic, and weaker models actually performed worse with skills than without. Our finding is a different failure mode: the skills fire every time, the agent reads them, and it still follows the existing code instead. Three different teams, three different failure modes, same conclusion — knowledge injection is not a solved problem.
Yogi Berra's original fork in the road was a circular street — both forks led to his house. This experiment found the same thing. The agent comes to a fork: the skill points left toward MockMvcTester, the existing code points right toward mockMvc.perform(). The agent takes it — the well-worn path, every time, both variants, all six runs. And we come to our own fork: simple prompt or hardened prompt? We take it. Both lead to T2 = 0.667. The destination was never determined by which fork you chose. It was determined by the road that was already paved.
This research is the basis for my workshop at Spring I/O Barcelona. Subscribe to get the workshop materials as soon as they're available.



