Agent Control Theory
Agents are taking on more of software development, and steering them turns out to be an old problem in disguise. The feedback loop that keeps them on course is nothing new. It is the founding idea of control theory. Now, let's point it at agents.

What do you think software development will look like in five years?
I don't know. As Yogi Berra supposedly said, "It's tough to make predictions, especially about the future."
What I do know is that software development today doesn't look much like it did a year ago. A year ago, most of us weren't routinely working with AI systems that write code, review pull requests, generate tests, modernize applications, and chase down production issues. Today, many of us are. The change isn't coming. It's here.
For most of my career, I've built frameworks, code that developers should not have to write over and over again. The job was to take verbose, hard-to-use APIs and turn them into something terse and flexible, so developers could focus on their own applications.
Now the abstraction boundary is changing. Agents are taking on more of the implementation I used to do by hand. I hardly write that code myself anymore. I still write a lot, just at a different layer - intent, designs, tests, constraints, judges, and the next intervention. The question I can't put down is: when more of development moves into agents, how do we keep that work on course?
That question is behind some news, which I'll put near the top because I know how far most of us actually read. After more than twenty years working on Spring, I'm leaving to pursue it full time. New roads. More soon.
So how do you work on a question like that, keeping agents on course? Not with predictions. Everyone has those. I'm less interested in predicting the future than in building prototypes of it and measuring whether they actually work. If a new workflow is better, show me the benchmark. If a new agent architecture is better, show me the experiment. Our industry has an abundance of opinions and a shortage of controlled experiments. What lasts won't be the most convincing prediction. It will be the ideas that survive contact with measurement.
The model matters, a stronger one lifts everything, which is why each frontier release lands like an event. But hand two teams the same model and you get wildly different agents. That gap is the key to answering the question.
For prototypes, that gap can be charming. For enterprise software, with real repositories, real risk, real review, and real maintenance, it is the difference between a demo and a system you can trust.
The people actually running agents thousands of times a day, not demoing them, have made "which model" the easy question. The hard ones are, is it working? how would I know? can I make it cheaper? and am I locked into the vendor? None is settled by a better model. Every one is a question about the loop, how the agent is built, run, and made better than its last version.
That does not make professional developers less important. If anything, it raises the value of judgment - what to build, how to constrain it, what evidence to trust, and how to know it actually worked.
And operating an uncertain loop under constraints is one of engineering's old disciplines, just not in our field yet.
The dark horse
The first thing to accept is that these systems are probabilistic. You never know exactly what path an agent will take through a repository, which files it will read first, or where it will need to recover.
But that uncertainty is not unusual. The weather is probabilistic. So is traffic. Adaptive cruise control does not know what the car ahead will do next, and Waymo does not know what every pedestrian will do. We trust systems like these anyway, not because they predict everything, but because they continuously sense, compare, and correct. That cycle of sensing and correcting is a feedback loop, the first thing any control textbook draws, and the discipline it gave rise to is control theory.
Control theory is the dark horse of modern life. It runs almost everything and is famous for almost nothing. A drone, an unstable object with propellers, stays in the air because it is being stabilized thousands of times a second. A chip fab turns dust-sensitive, temperature-sensitive chemistry into working silicon because every wafer teaches the next wafer how to be better. It balances the power grid. We mostly notice it only when it fails, when the car skids or the grid goes dark. Its greatest achievements look like nothing happening at all.
AI is the newest system of this kind. The model is the face everyone sees. Control is the nervous system. The model recognizes the pedestrian, while control decides what the machine should do now, safely, smoothly, under constraints, and with imperfect information. So wherever AI acts in the real world, there should be a control system under it. In my experience, many AI systems shipping today do not have one. Even the teams that come closest tend to build the loop by feel, without the underlying theory that would tell them why it works.
The coding agents we run today are this kind of machinery. They read code, run commands, call tools, modify real repositories, and act on the world. In the language of control theory, they are the plant, the system you are trying to steer. The word comes from the power and chemical plants where the discipline grew up.
An unusual plant, yes. You do not steer a coding agent thousands of times a second the way you stabilize a drone. You improve it between runs, the way a fab improves the next wafer from what the last wafer taught. The trajectory is slower, more episodic, more human-gated, but it is still a trajectory, a path through states, observations, tool calls, mistakes, recoveries, and eventual success or failure. Once you can see an agent's run that way, the questions change. The question is no longer only whether it succeeded. It becomes where it went, where it looped, where it stalled, and what should change so the next run is better.
Sometimes the answer is obvious from the verdict. Sometimes you need to go deeper into states and transitions. Once you view a run through this lens, you can model where the agent spends its time and what it will cost to reach a result the jury verifies as correct, which is how you tell real progress from wasted effort.
Seeing the run as a trajectory, using the verdict as feedback, and choosing the next intervention are the pieces of what I call Agent Control Theory. The rest of this is the mapping of those ideas into practice, into the actual work of building agentic systems. And that mapping has a shape, it's a loop.
The loop

The agent is the plant, a workflow of deterministic and AI steps. The evidence ledger is the feedback path, built from the immutable journal, workspace artifacts, and derived evidence. A cascaded jury compares that evidence against the spec and returns score, reason, and evidence. The observer models the trajectory with Markov analysis to see how the run spends its effort, where it loops and where it stalls. Together, the jury and observer produce the verdict and diagnosis the controller needs to choose the next intervention. The loop closes when that intervention changes the next run.
The picture is simple, but it changes the posture. If the agent is the plant, then the first job is to see what it did. A final result tells you almost none of that. A transcript tells you more, but still not enough. What you need is the run itself, recorded as evidence.
The evidence ledger is the feedback path. Its immutable core is the journal, the step-by-step record of what the agent actually did. Around that are the artifacts the run produced or changed, including code, diffs, tests, logs, build results, coverage, costs, and derived evidence created after the run.
The spec is the reference. The cascaded jury compares evidence against that spec and returns score, reason, and evidence. The observer models the trajectory. A Markov model shows where the agent tends to go, and the expected work remaining read from that same model estimates how much more it will churn before it stops.
Together, the jury and observer produce the signal the controller needs, the verdict and diagnosis. The verdict says how the run scored against the spec. The diagnosis helps decide what to change next. Today the controller is often a human. Over time it can also be an agent supervisor choosing the next intervention. That is the loop as a diagram. The rest of the work is putting real software behind each box.
Software behind every box
AgentWorks is the software around the model. It is my attempt to put a library behind each box in that loop, turning a run into evidence the controller can act on.
In that diagram, "agent" does not mean "a prompt." It means a structured workflow with an agentic core. Some steps are deterministic because they should be. Some steps use an agentic CLI because judgment is needed. The important part is that a system like this can be measured and improved, while the model stays fixed.
The agent needs structure, so Agent Workflow builds agents as workflows of deterministic steps and AI steps, rather than one giant prompt hoping for the best. Many of those AI steps need a portable way to drive real coding harnesses, so Agent Client provides one API for Claude Code, Gemini CLI, Codex, and others.
The evidence ledger needs an immutable core, so Agent Journal records what the agent actually did. The jury needs instruments, so Agent Judge provides executable evaluation that returns score, reason, and evidence, not just opinion. The observer is the analysis layer over that evidence, with a Markov model of the trajectory and the expected remaining work read from it.
The loop also needs discipline around it. Agent Experiment runs controlled comparisons. Agent Bench turns a stabilized jury into a reusable rubric for comparing agents on real software work, not leaderboard puzzles. Agent Hooks gives the controller deterministic places to intervene at the tool boundary.
The controller is the box that turns a verdict and a diagnosis into the next move, the choice of which lever to pull. Everything else in the stack gathers evidence, and the controller decides what to do with it.
One project sits slightly outside the diagram but behind all of it, Agento Forge. Forge is the design-led agentic development method I used to build the stack itself. I wrote and revised the intent, the designs, the tests, and the constraints. The agents wrote judges, workflow stages, library code, docs, and glue code against them. In practice, when I needed a judge, the agent wrote a judge. When an experiment needed another workflow stage, the agent added one.
That is a different loop from the one used to improve an agent's behavior. The plant is the software system being built, and the feedback comes from tests, builds, docs, and human design review. But it is the loop that made the experimental apparatus possible.
AgentWorks is organized around the boxes the loop requires. A controlled agent needs the agent itself, the evidence ledger, the jury, the observer, the controller, and the benchmark. Calling a model is only one component.
The thesis behind AgentWorks is simple. The model does not run the system. The system runs the model.
The agentic CLI is the new harness
In the first era of AI applications, building one usually meant writing code around a model endpoint. You called the API, passed a prompt, parsed the response, added tools, added retries, added context management, added tracing, and slowly assembled your own loop. That was a reasonable place to start when the model endpoint was the main primitive, but it is not where I would start today.
The new harness is the agentic CLI. Claude Code, Gemini CLI, Codex, Amazon Q, and other coding agents already know how to read a repository, edit files, run commands, call tools, ask for permission, and keep a working loop alive. They are model-plus-harness systems, with tools, context, permissions, feedback, and execution wrapped around a model so it can do work.
The tool question moves up a level. The question becomes which tools agents should use so their work is visible, constrained, repeatable, and efficient.
That matters because most teams do not yet know the shape of the agent they need. They know the pain. Missing tests, pull requests that need review, services that need modernization, and builds that keep failing. But if they start from lower-level model calls, they still have to build repository access, shell execution, file editing, context management, permission checks, logging, retries, and failure recovery around the model. Those details are not incidental. They are where much of the agent's behavior comes from.
An agentic CLI lets you discover that shape on real work before you prematurely turn it into a bespoke application. You can run the CLI, journal what it does, judge the result, find the loops, the waste, the missing knowledge, and the unsafe tool boundary, and then decide what deserves to become software.
Agent Client drives the agentic harnesses people are already using, whether that is Claude Code today, Gemini CLI tomorrow, or Codex next week. It treats repository access, file editing, shell execution, permissions, context management, and the coding loop itself as higher-level primitives rather than plumbing every team has to rebuild.
Swapping vendors matters, but the larger point is time to useful work. If an agentic CLI already has the working loop, start by driving it through an API, journaling what it does, judging the result, and using the evidence to decide what needs to become bespoke software.
The journal anchors the evidence ledger
A transcript tells you what the agent said, while a journal tells you where it went. That distinction matters because most of the useful evidence in an agent run is not in the final answer, and not even in the conversation. It is in the path the agent took, the files it read, the tools it called, the commands it ran, the mistakes it recovered from, the places it stopped to reorient, and the loops it could not escape.
Agent Journal turns a run into structured evidence you can replay, inspect, judge, and compare. It is the immutable trace at the center of the evidence ledger. Once the run is journaled, the agent becomes a trajectory.
The image below is one of my favorite ways to see that. Each cell is a step in the agent's work. Read left to right, and the run becomes visible. You can see where it searched, where it wrote, where it built, where it verified, and where it burned time just trying to figure out what to do next.
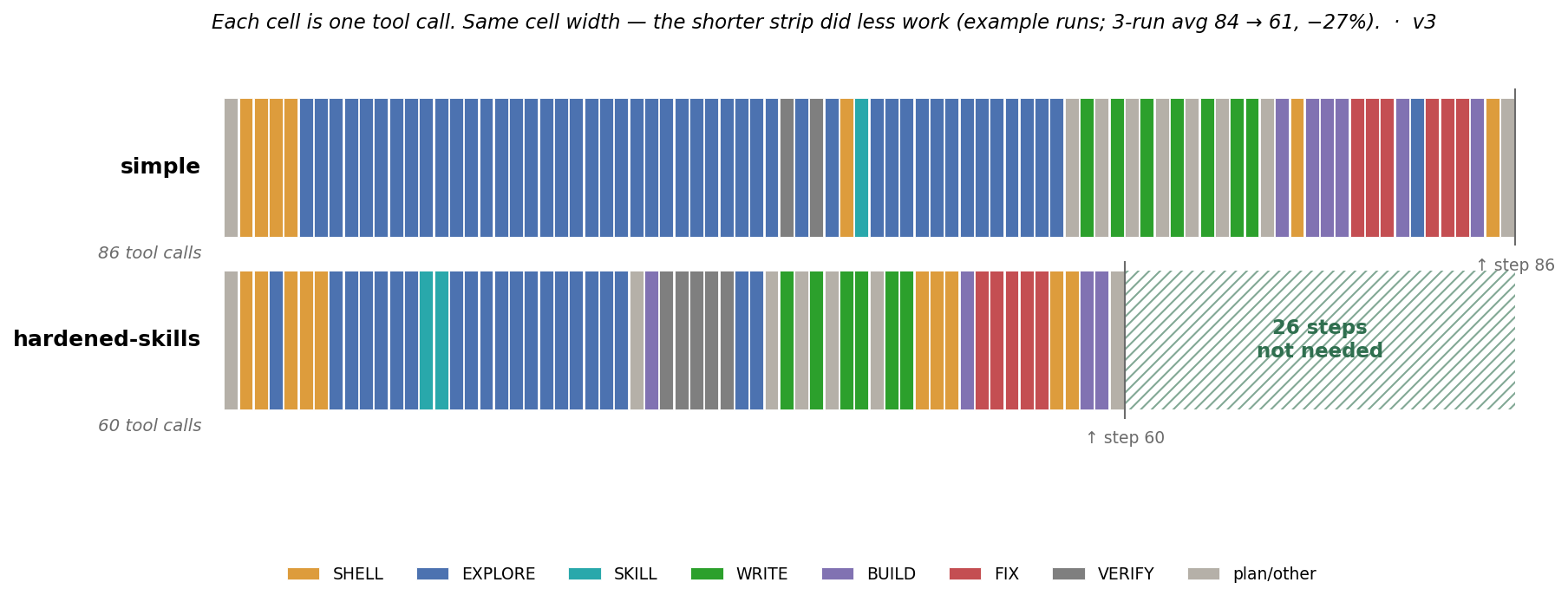
A journaled agent run as a work trajectory. Each cell is one step in the work, making visible where the agent searched, wrote, built, verified, reoriented, and recovered.
Once the trajectory is visible, success becomes only the first question. The journal also shows where the work went, what the agent had to do to get there, and where a failed run was pulled off course.
The trajectory has structure
Once you have the trajectory, you can model it by taking each step in the journal and assigning it to a state such as exploring, reading, writing, building, verifying, or recovering. Then you can ask a simple question. When the agent is in one state, where does it tend to go next?
The result is a transition matrix, a map of the agent's habits based on what it actually did rather than what it said it was doing.
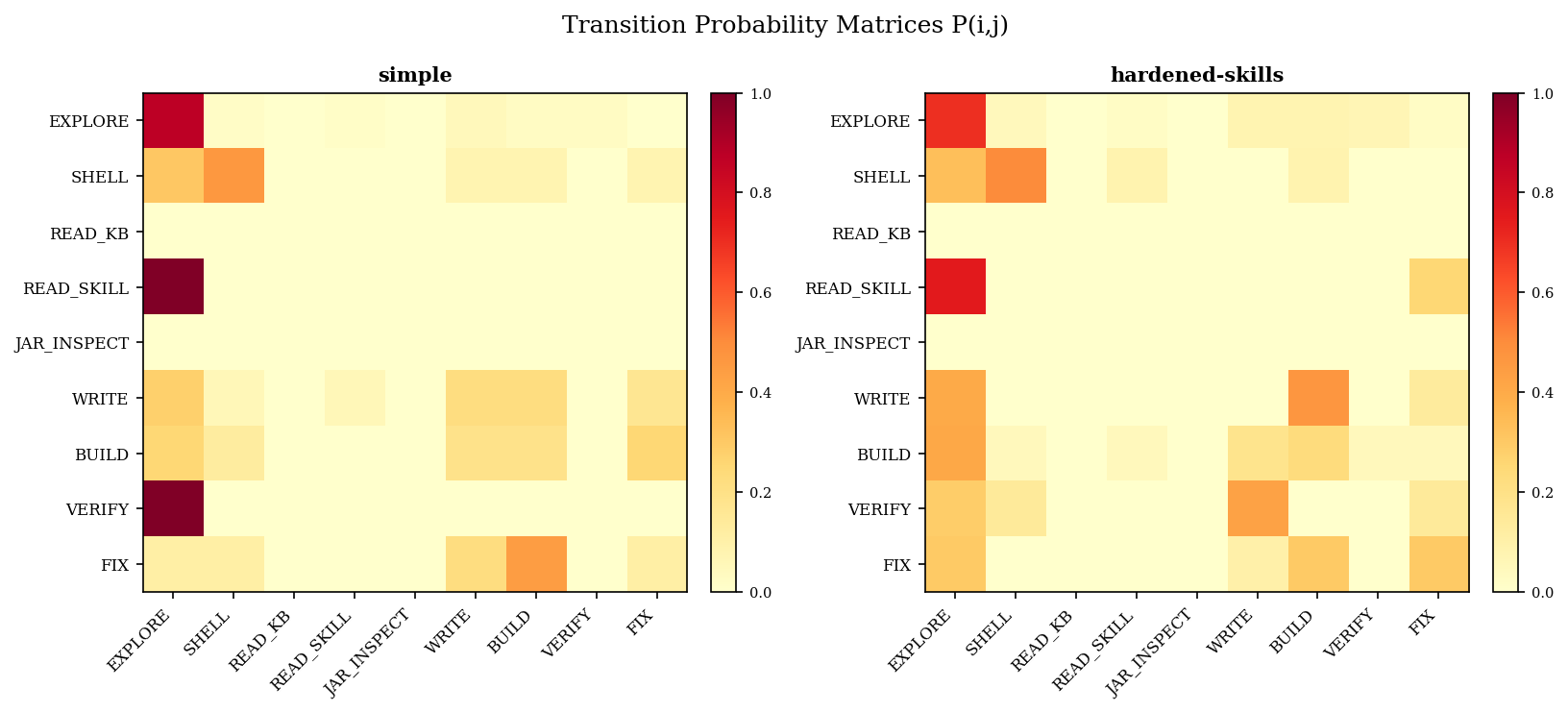
The agent's habits, before and after. Each cell shows how often the run moved from one kind of work to the next, with darker cells meaning more often. On the left, the simple prompt keeps falling back into EXPLORE. On the right, hardened+skills reduces that stickiness and the run spreads more naturally into writing, building, and verifying. Nobody told the agent to explore less. It simply no longer needed to.
The matrix starts to earn its keep here. It shows where the agent gets stuck, whether it moves from exploration into production work, and whether a change actually altered the behavior of the run rather than just making the transcript look cleaner.
Markov analysis creates the habit map showing where the agent tends to go. From that same matrix you can read a single number, the expected steps to done from the EXPLORE state, which makes two runs easy to compare. That number is not a separate measurement. It follows from the matrix, and tracks one habit almost entirely, how often the agent falls back into exploration.
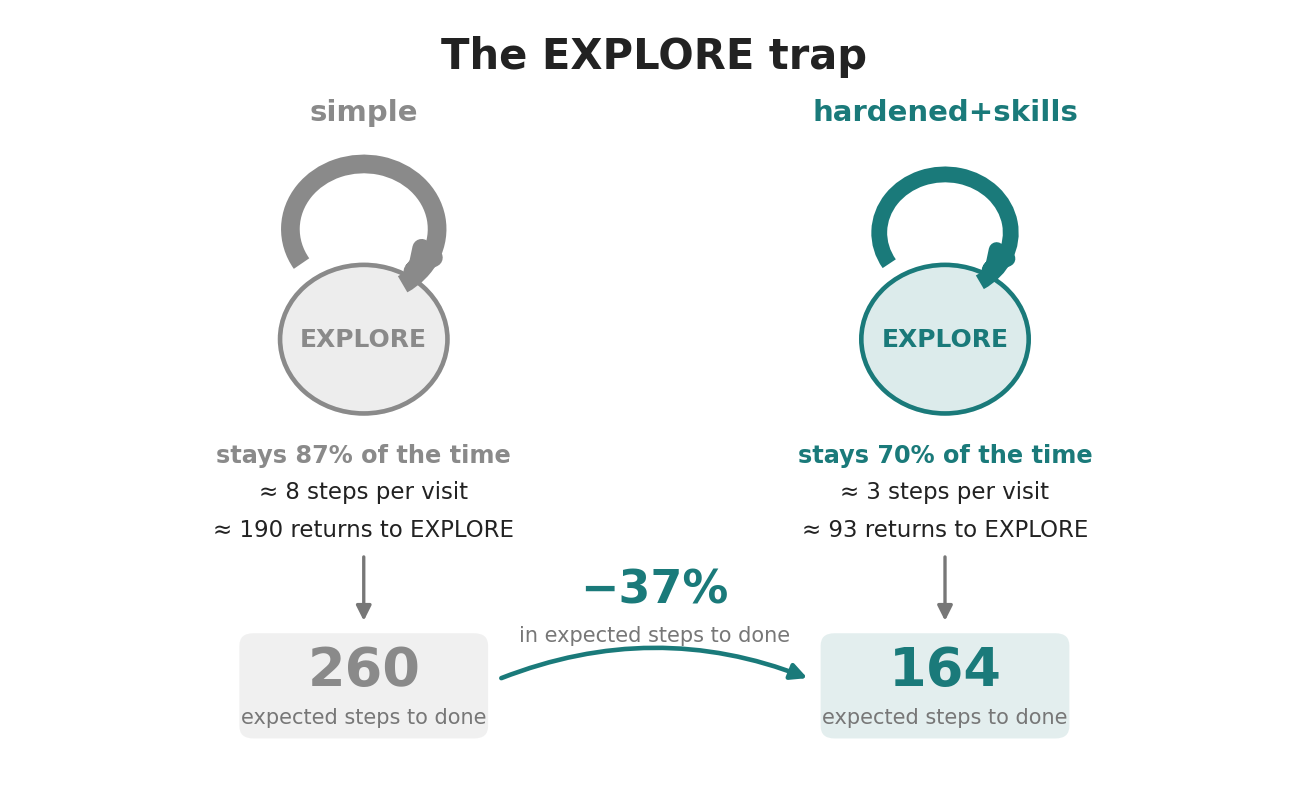
The EXPLORE trap. When the agent lands in EXPLORE, the simple prompt keeps it there about 87% of the time, so it keeps falling back to reorient instead of moving on. The hardened prompt loosens that self-loop to about 70%, and the expected work to done from EXPLORE falls with it, from about 260 steps to 164. That number is the self-loop re-expressed - fewer returns to EXPLORE, so fewer redundant reads and fewer tool calls overall.
The loop points to the next lever
That EXPLORE drop was a real turn of this loop. The expected work from EXPLORE fell from about 260 steps to 164 because of an experiment I published earlier this year, comparing a bare prompt with a hardened one on the same test-writing task. The hardened run cut the orientation tax. Averaged over three runs each, redundant reads fell from about 17 per run to about 4, and raw tool calls from about 84 to 61, with no change in judged quality.
Cost dropped, but quality did not. The judge scored each run on its own, and the same two criteria, version-aware patterns and domain-specific patterns, stayed at the floor every time. The ceiling was the code. The agent read the skill, read the older tests already in the repo, and followed the examples in front of it. The skill taught the newer pattern in plain markdown, but the codebase taught the louder lesson.
That is where the controller comes in, and on this turn the controller was me, reading the verdict and the diagnosis and deciding what to change. The diagnosis pointed past the prompt to the shape of the workflow. The task was really two jobs tangled into one - update the existing tests to the latest testing API, and increase coverage. Fused into a single step, the coverage agent imitated whatever tests it found, old API and all.
So the implication is simple. The agent copies whatever examples are in front of it, so the move is to give it better ones. Upgrade the existing tests in their own step first, then run the coverage agent against the examples you now want it to copy. The useful result was not that the hardened prompt won. It was that the prompt cut cost, the judge exposed a ceiling the prompt could not move, and the evidence named the next change.
That is one full turn of the loop. A verdict, a diagnosis, and a clear next move. But that move was one lever out of a much larger set. So how do you think about the whole set, and about what you are really changing when you pull one?
Levers, and the policy beneath them
Choosing what to change next, which lever to pull, is the controller's whole job. For now that controller is usually a person reading the verdict and the diagnosis, and over time more of the choice can move to an agent supervisor. The coverage run pointed to two of them. Loosen the orientation tax with a better-shaped prompt, and fix the examples in the codebase with a new workflow step. So what is the full set to choose from?
The first levers I learned to reach for, in order, were the cheap and structural ones. The prompt, then the knowledge and skills, then the shape of the workflow, then the steering at the tool boundary, and only last the model itself.
Those five are all one kind of lever, because they all change what the agent does. The full set is wider, and it helps to sort it by what each one actually touches.
- What the agent does: the prompt, the skills, the workflow, the tools, the model.
- What you can see: a sharper or new judge. This one does not change the agent's behavior at all. It changes your ability to tell good work from bad, which is why it often comes first. You cannot steer toward a target you cannot measure, and the coverage experiment only found its ceiling once the judge got sharp enough to show it.
- What the agent works from: the code already in the repository. The skill spelled out the newer pattern, but the agent copied the old tests in front of it anyway. More knowledge was not the lever. The fix was structural. Upgrade the existing tests in their own step, so the coverage agent has the right examples to follow.
- Work that leaves the loop: when a step becomes reliable enough, you promote it from a judgment the model makes into deterministic code. The cheapest agent step is the one the agent no longer has to take.
Control theory names the two sides, feedforward for the predictable part and feedback for the rest. Promotion moves work between the two.
Underneath all of them is a single object. When you change the prompt or the skills or the tools, what you are really editing is the agent's policy, its rule for deciding what to do next. Control theory has a clean name for that rule. A policy is a feedback law, and a feedback law is the controller.
A coding agent is different from a thermostat. You cannot open a language model and read its mind. So you steer it from the outside. The policy is yours, the prompt and skills and workflow you write to shape what the agent does. The mind you never see. What you get instead is its footprint. The transition matrix from the journal is the trace the agent leaves as it moves through a handful of states - exploring, writing, building, verifying. Change the policy, and that footprint changes shape. The matrix was never the model's mind. It is the shape that mind leaves when it works.
If you come from reinforcement learning, this is familiar ground. The run is a trajectory, the journal records the transitions, the judges define the cost, and pulling a lever is policy improvement. The one twist is where the learning lives. The base model's weights never move. The improvement happens in the system around the model, in the prompt, the knowledge, the tools, the judges, and the workflow. Same model, better policy.
Cost and lock-in
The method pays for itself at scale. The expensive part of an agent comes from running it thousands of times across every pull request, failing build, modernization task, and repository in a portfolio. At that scale, wasted orientation is not a curiosity in a chart. It becomes a bill.
Control theory calls this the cost-to-go, the total cost the loop expects to spend before the jury verifies the result as correct. But "cost" here is doing more work than the word lets on. It isn't the token bill. It's multi-objective — a cost function you define yourself, to fold in everything you care about at once. In my work I've focused on two things. The tokens you spend, and whether the jury passes the result. That's the idea that transfers straight from control theory. Pick what counts as cost, then minimize it.
A coding agent spends much of runtime finding its footing by reading files, searching APIs, checking assumptions, running commands, and recovering from wrong turns. Some of that orientation is necessary. Some of it is just the agent guessing because the system around it failed to provide the right shape, context, tool, or constraint.
Cost becomes a control problem once the run is journaled, judged, and compared across variants. Then you can ask where the tokens went. Did the change reduce wasted exploration? Did it merely look better, or did it shorten the trajectory? Did it move work out of the model and into deterministic code? The answer does not have to be a vibe. It can be measured.
The same apparatus changes the lock-in story. If the judges become a benchmark, the agent underneath becomes a swappable engine. You no longer have to argue about whether one vendor's agent is better than another's. You run the same task, under the same judges, against the same evidence, and compare the result.
The enterprise value of the loop is that it does not ask you to believe one model, one vendor, or one harness will win forever. It makes the swap an experiment, not a leap of faith. You can find the right agent for the job, capable enough, cheap enough, and controllable enough, and prove it.
From a discipline to a product line
A discipline earns its keep when it builds something, and Agent Control Theory is how I build agents. I start with the loop, instrument the run, judge the result, model the trajectory, choose the next intervention, and measure again. I pointed it first at Spring because that is where my roots are. The method is not about Spring, but Spring is where I can prove it fastest, on codebases I know cold.
That work has become Bud Spring, a family of agents for controlled software work.
- Bud Spring Initialize starts a new service, application, or repository on a clean foundation.
- Bud Spring Actualize turns specs, backlog, and product intent into working software.
- Bud Spring Optimize improves structure, coverage, reliability, and maintainability without changing what the software is supposed to do.
- Bud Spring Modernize brings legacy systems forward through framework upgrades, dependency and CVE remediation, and the slow tax of staying current.
A sibling project, Bud DDD, applies the same method to domain-driven-design review without tying it to Spring, Java, or any single framework.
Each Bud carries the control loop underneath it with an evidence ledger, a cascaded jury, a benchmark, and a record for every move. Generation is only one part of the job. The Bud products were also built that way. Agent Control Theory improves the behavior of the agents, while Agento Forge builds the software, tests, judges, knowledge, and workflows around them.
Control theory has a precise question behind "will this lever help". Controllability. Whether your levers can actually move the agent to where you want it. Not every goal yields to every lever. Some you reach by changing the prompt, some only by changing the code the agent imitates or the shape of the workflow, and some you cannot reach at all until the underlying model improves. Working out which lever reaches which goal, before you ship, is the real substance behind characterizing an agent rather than trusting a demo.
The larger arc is Agento University, the place where agents are grown, characterized, and eventually operated. It is also the ledger where journals, judge verdicts, rubrics, failures, interventions, and promotions become durable evidence instead of anecdotes. An agent should not graduate because it had one impressive run. It graduates when you know where it works and where it does not, where it succeeds, where it drifts, where it gets stuck, and when a human needs to step in. The question is whether it stays reliable across the variety real repositories throw at it, which is why a benchmark has to span many of them, not one.
You could think of this as post-training for the agent layer. The base model may stay fixed, but the agent keeps learning through journals, judge feedback, benchmark tasks, interventions, and deployable skills.
Over time, that becomes less a chat window than a control room, with a working population of characterized agents tending real codebases by maintaining, reviewing, modernizing, and escalating high-risk decisions to humans.
Spring is the first proving ground, not the boundary of the idea. I believe that agentic software work should be something you can instrument, judge, compare, improve, and supervise. This post lays out the theory. The next one puts it to work.
I still don't know what software development will look like in five years. I intend to find out the way this whole post suggests, by building it, measuring it, and keeping what survives.
Next month, I'll be working independently and partnering with organizations that want to put these ideas into practice, including agent evaluation, modernization, and feedback loops that actually measure. If you're wrestling with those problems, or have hard ones worth taking on together, I'd love to talk. You can reach me at mark@pollack.ai.



